
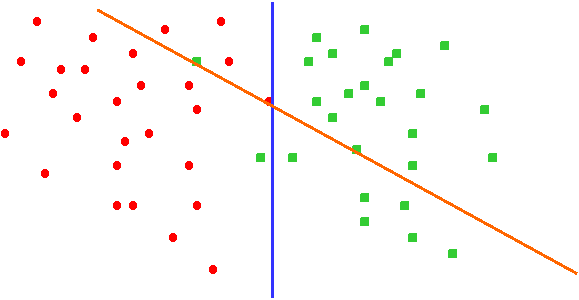
Chemgenome is based on the hypothesis that both the structure of the DNA and its interactions with regulatory proteins and polymerases decide the function of a DNA sequence. It uses a simple three-parameter model based on Watson- Crick hydrogen-bonding energy, base-pair stacking energy, and a third parameter which is related to Protein-Nucleic Acid interactions. Each of these parameters acts as a dimension for a three-dimensional unit vector, whose orientation differs for each trinucleotide. Imagine if you were to separate coding DNA from non-coding DNA. Lets imagine that we found a way to represent each DNA sequence as a dot on a 2D plane. All the coding DNA sequences are represented as Red dots while the non-coding DNA sequences are represented as Green dots, as below.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
We can separate the two clusters of dots using a line. In Fig 2, we can see two separating lines, but evidently the blue line separates more effectively than the green line. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Once we get this line, all we have to do is convert a new DNA sequence into a point and then check on which side of the line it lies. If it lies on the side with the red points, then it is a gene else it is a non-gene. Hence, the problem of DNA evaluation in 2D space boils down to
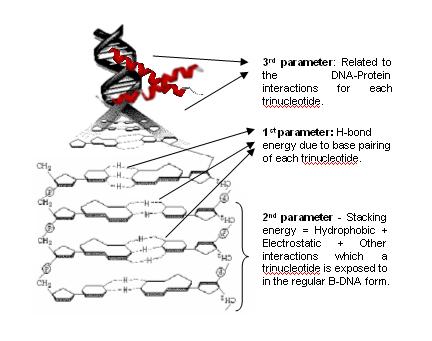
This problem, when extended to 3D space involves representing DNA as a vector and find the best separating plane to separate these vectors. But how do we represent a DNA sequence as a 3D vector? This is where the physico-chemical model comes into picture. DNA sequence is made up of set of four bases (A,T,G,C)which combine in different possible manner to give 64 unique codons. Each of the 64 codons(trinucleotides) are assigned a X(Hydrogen Bonding Energy),Y(Stacking Energy) and Z(protein-Nucleic acid interaction).
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Every sequence is broken down into trinucleotides, the three components for each trinucleotide are added up. The values assigned to all the trinucleotides are normalized to lie in the range [-1,1]. These unit vectors are then plotted on unit spheres. A physical separation of the vectors corresponding to coding DNA sequences and the non-coding DNA sequences was observed. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
This physical separation of the vectors corresponding to genes and non-genes is the basis of the physico-chemical model of Gene Evaluation. Once the best separating plane is obtained, we only need to check if the new DNA sequence lies on the Gene side of the plane or the other side. Such an evaluation has proven accurate for Prokaryotes to an accuracy of >95% and forms the basis of Chemgenome 1.1.
Chemgenome 2.0 goes a step further and predicts the coding regions in Prokaryotes if a whole genome or part of genome is given as an input. To know more about this physico-chemical model, refer to [Dutta, S., Singhal, P., Agrawal, P., Tomer, R., Kritee, Khurana, E. and Jayaram, B. A Physico-Chemical Model for Analyzing DNA sequences. J. Chem. Inf. Model., 2006, 46(1), 78-85. ] ABSTRACT |
